
Congratulations on Corpling lab's system DeDisCo winning the DISRPT 2025 Shared Task on Discourse Relation Classification!
Congratulations on Corpling lab's system DeDisCo winning the DISRPT 2025 Shared Task on Discourse Relation Classification!

Our paper presenting the UD Old English corpus of Cairo sentences , the first UD corpus of Old English, was accepted at SyntaxFest 2025 !
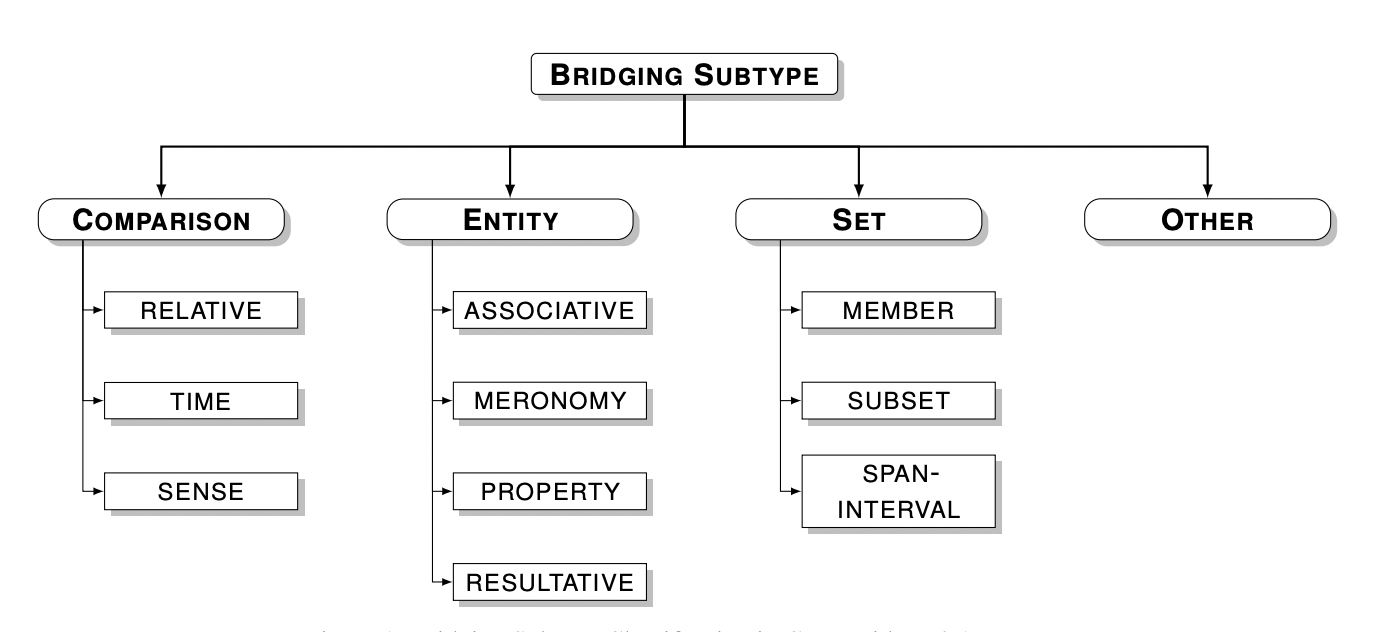
Our work on subjectivity in the anonotation of bridging anaphora will be presented during LAW XIX at ACL 2025!
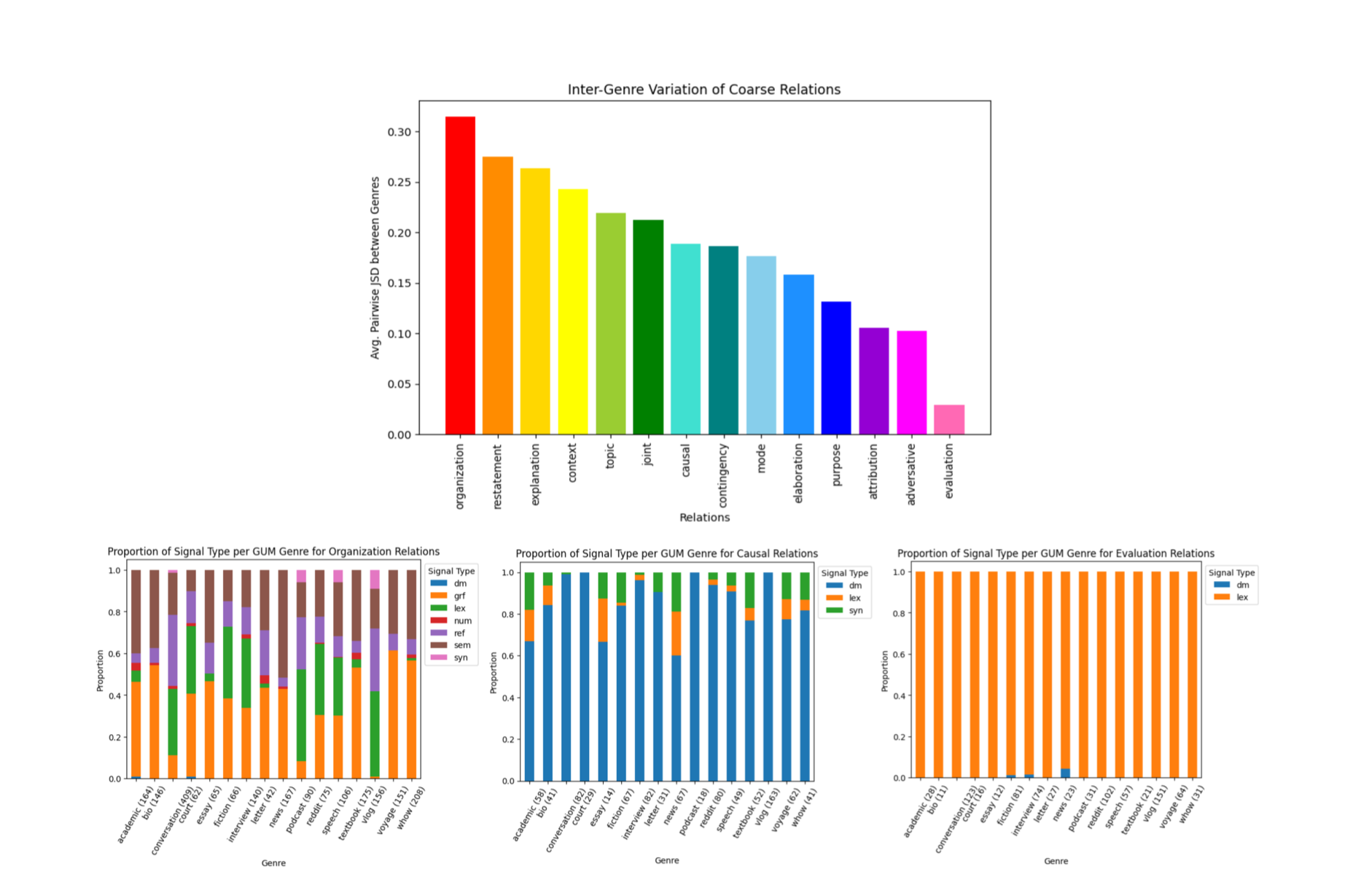
Our work on the inter-genre variation of discourse relation signaling in RST was accepted to SCiL 2025 !
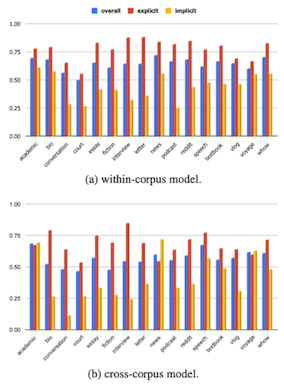
Our EMNLP 2024 paper presents a valuable genre-diverse PDTB-style dataset for English shallow discourse parsing across modalities, text types, and domains using a cascade of conversion modules leveraging enhanced RST annotations, thereby also enabling theoretical studies of discourse relation variation across frameworks

In our Machine Learning for Ancient Languages (ML4AL) workshop paper , we present a bidirectional RNN model for character prediction of Coptic characters in manuscript lacunae and use it to rank the likelihood of various textual reconstructions. A live demo of our models is available here !

Our EACL 2024 paper promotes a strict definition of entity salience by presenting GUMsley, a 12-genre challenge dataset for entity salience evaluation and shows how salient entities added to summarization models are beneficial for deriving higher-quality summaries with fewer hallucinated entities
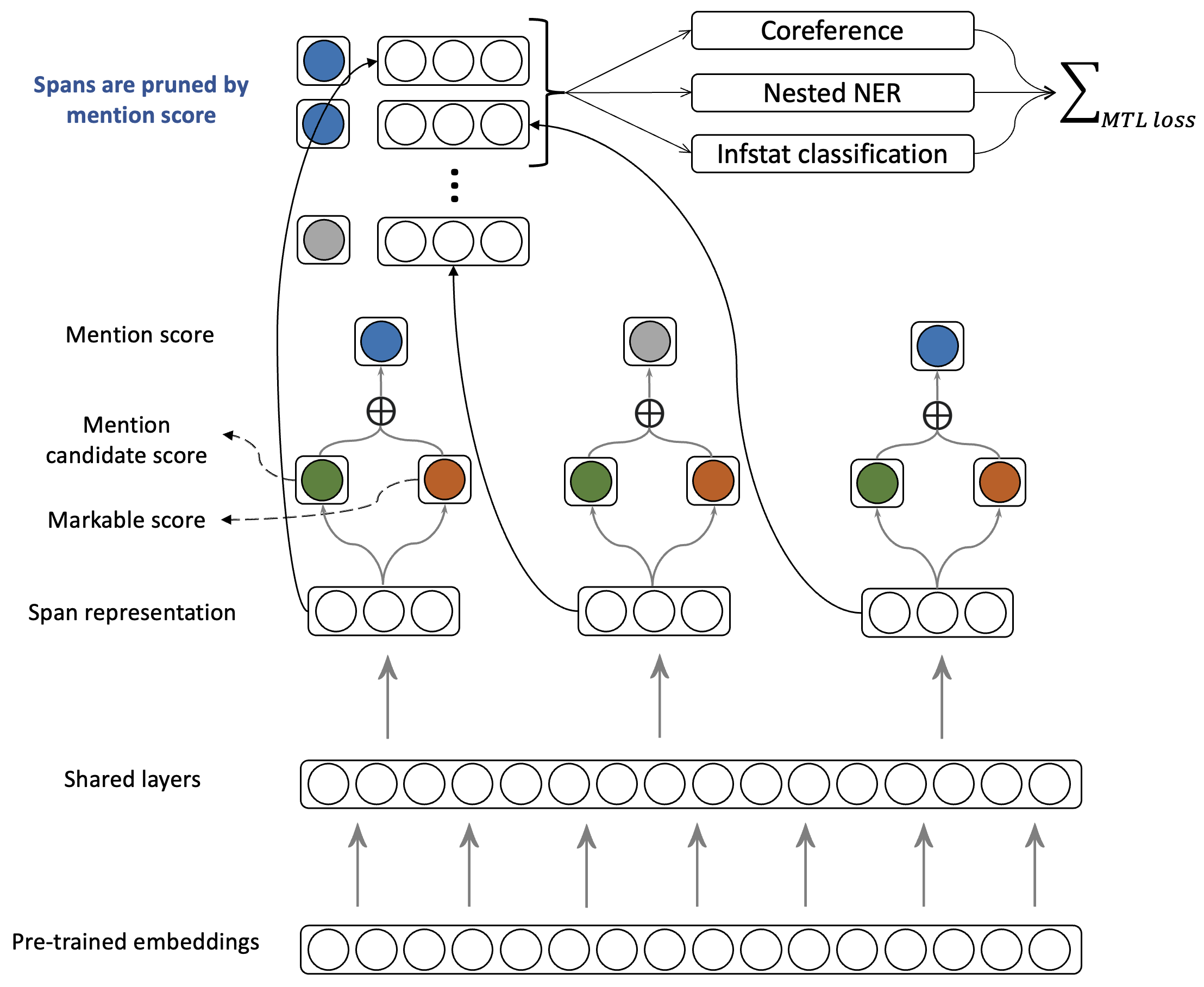
Check our AACL-IJCNLP 2023 paper about incorporating singletons and mention-based features to improve coreference generalization
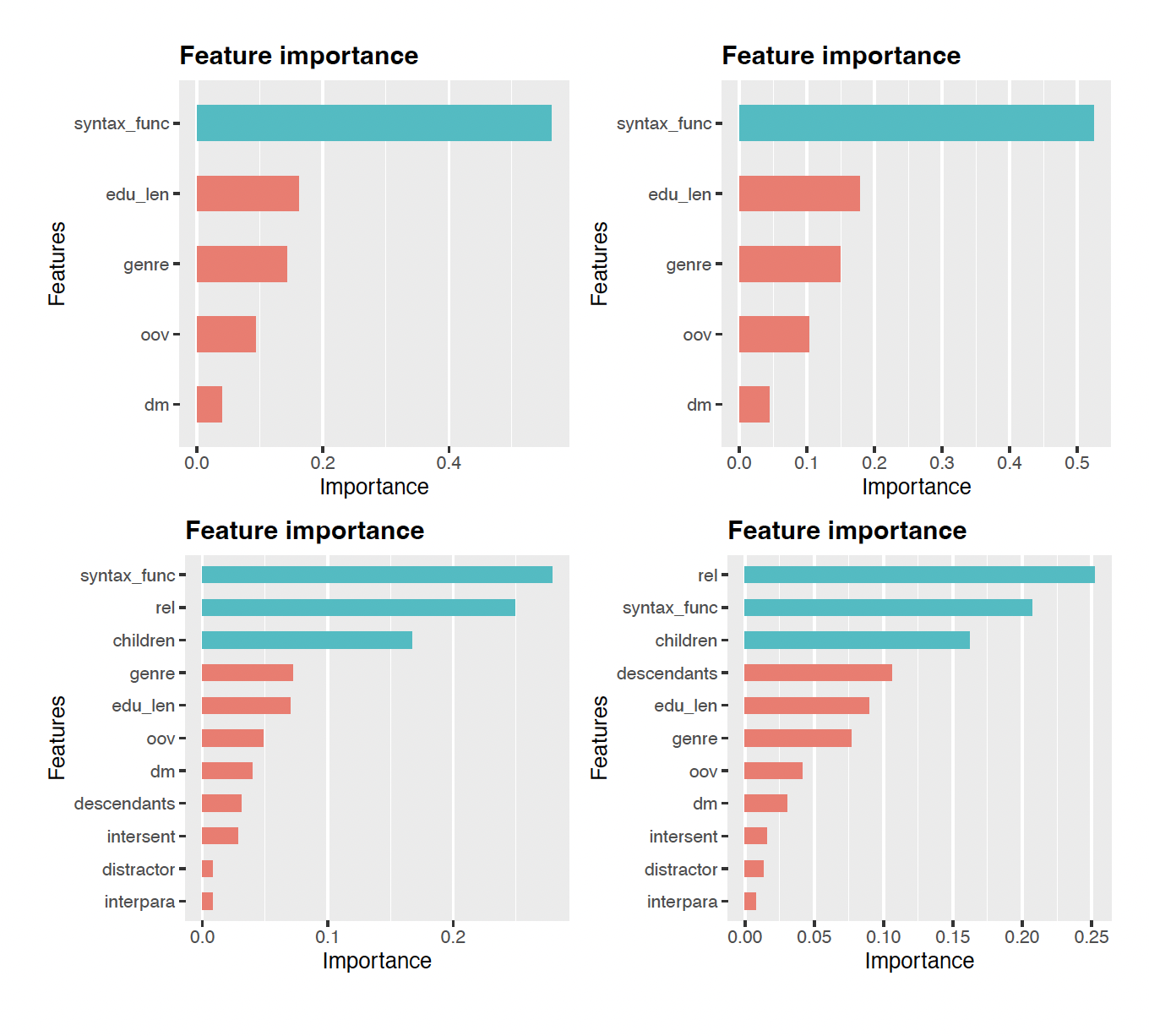
Our SIGDIAL 2023 paper on English RST parsing errors examines and models some of the factors associated with parsing difficulties
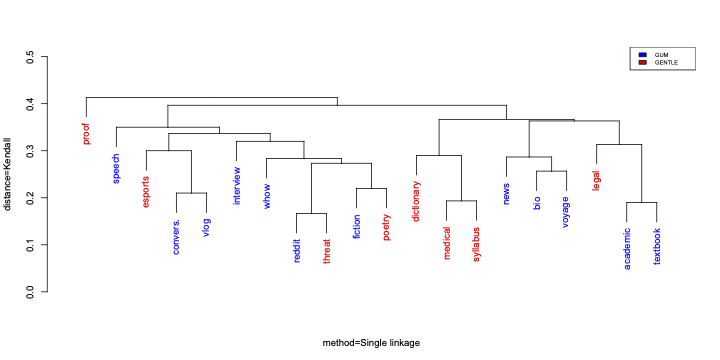
Our LAW-XVII 2023 (co-located with ACL 2023) paper on a Genre-Diverse Multilayer Challenge Set for English NLP and Linguistic Evaluation presents GENTLE , a new mixed-genre English challenge corpus totaling 17K tokens and consisting of 8 unusual text types for out-of-domain evaluation and openly released as part of the Universal Dependencies 2.12 version available here

Our ACL 2023 Findings paper on Multi-Genre Data and Evaluation for English Abstractive Summarization presents a 12-genre challenge set for English abstractive summarization (the extreme summarization task) following both generall and genre-specific guidelines
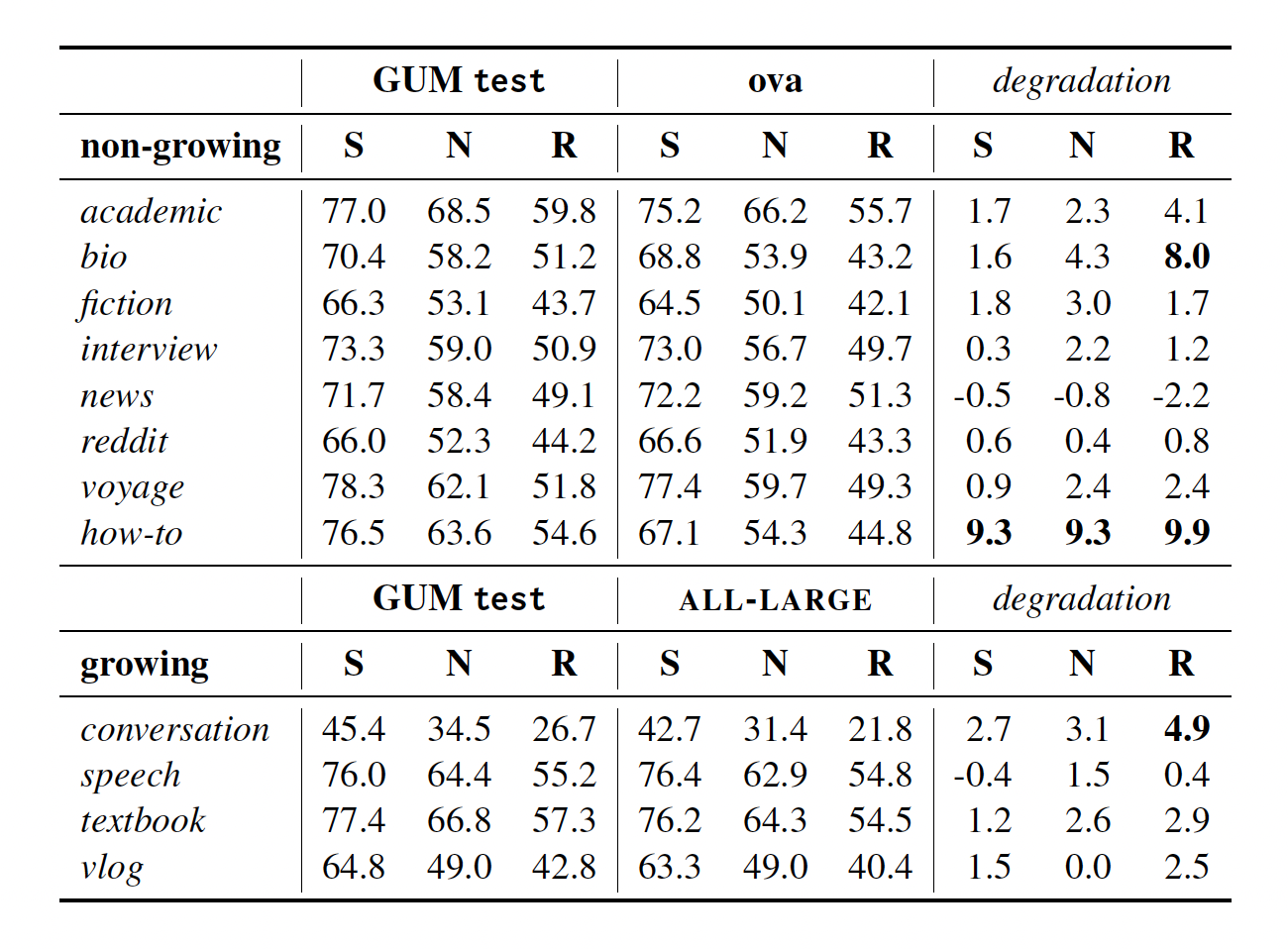
Our EACL 2023 paper on a thorough investigation of RST generalizability issues, with a focus on the impact of data diversity, thereby promoting multi-genre benchmarks for RST parsing based on our experimental results
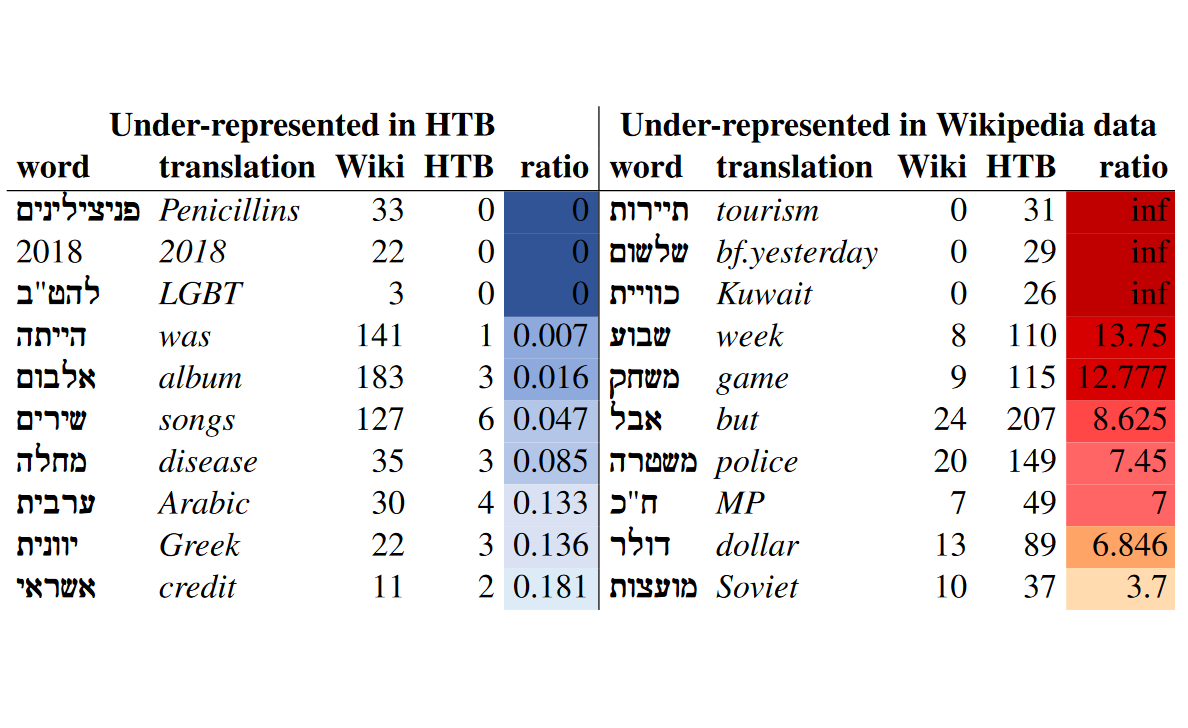
Our EMNLP paper on cross-domain treebanking and parsing for Hebrew has new SOTA parsing results and presents a brand new UD Hebrew dataset
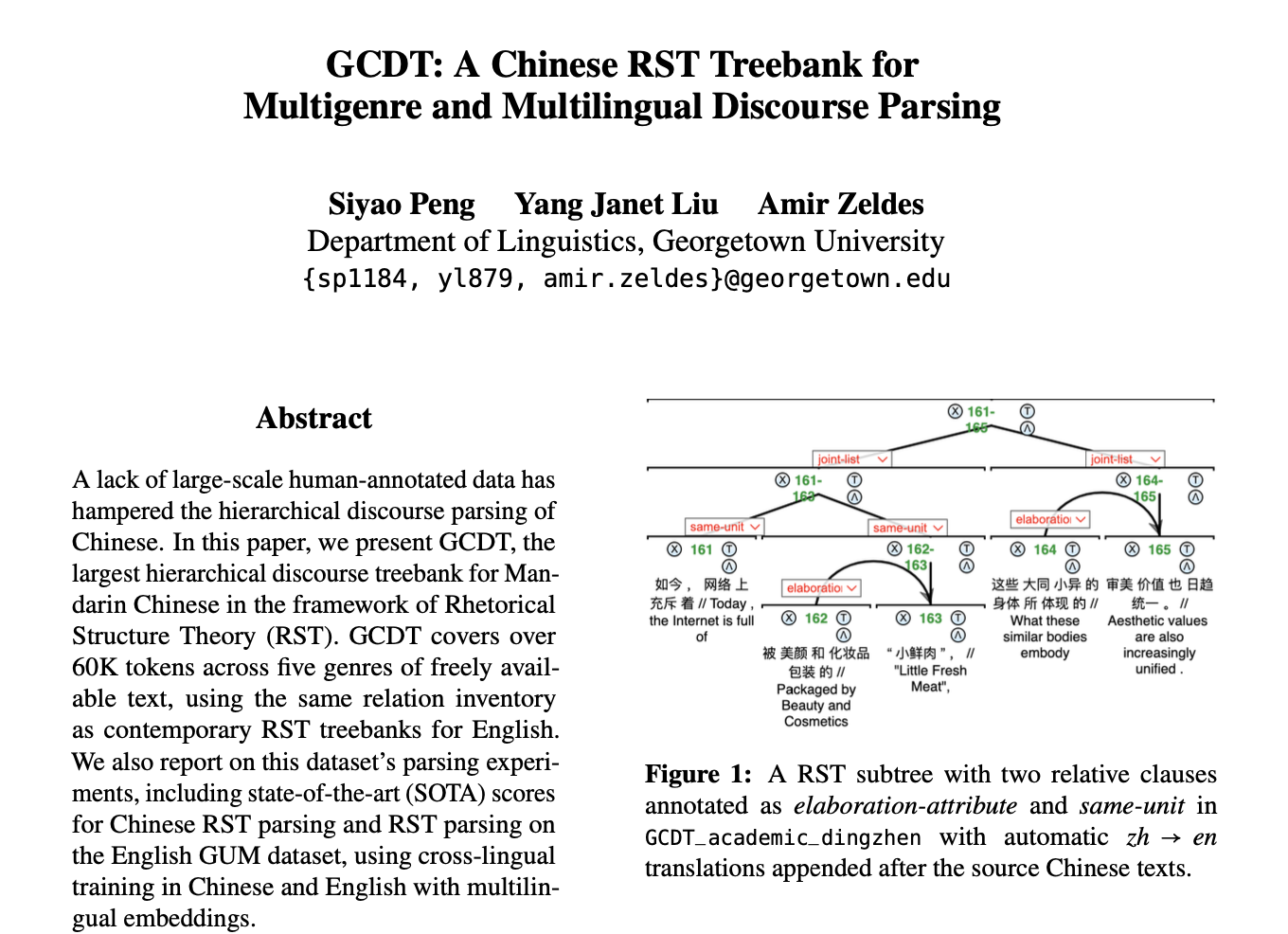
Check out Logan & Janet & Amir's arxiv paper for the largest Chinese RST dataset to be presented at AACL 2022

Congratulations on Corpling lab's system DisCoDisCo winning the DISRPT 2021 Shared Task on discourse relations!

Check out our ACL paper about generalization in SOTA coreference resolution, including the new OntoGUM dataset for evaluation.

Please join us online for Digital Coptic 3 , the virtual workshop for DH project on Coptic!

Would like to have more data to work with? Check our LREC paper , where we present a freely available, genre-balanced English web corpus totaling 4M tokens and featuring a large number of high-quality automatic annotation layers, including dependency trees, non-named entity annotations, coreference resolution, and discourse trees in Rhetorical Structure Theory.
2020-06-07
Shabnam and Amir's paper on Reddit part of speech tagging was accepted to WAC-XII .
2020-05-18
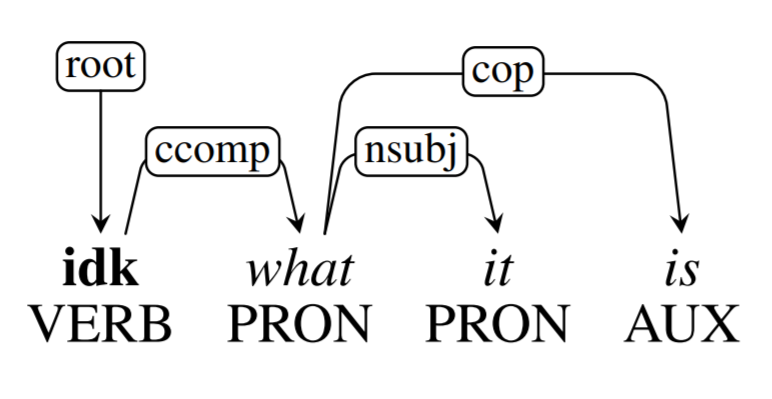
Thoughts on how to treebank social media? Read our LREC paper
2020-03-05

The Coptic Dictionary Online won the 2019 DH Awards for Best DH Tool!
2019-08-10

RFTokenizer now supports Arabic
2019-08-01
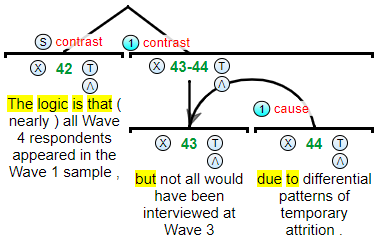
rstWeb 3.0.0 is out with discourse signal annotation support ( paper )
2019-04-11

GumDrop scores 3 second places and 1 first place at the DISRPT2019 shared task
2019-03-21

GUM version 5.0.0 has been released!
2019-01-21

The DISRPT 2019 shared task data on discourse unit segmentation is online
2018-12-09

Janet and Amir will present a paper about anchoring discourse signals in RST-DT at SCiL 2019
2018-09-21

Logan, Janet and Amir are presenting 3 papers at AACL2018 in Atlanta
2018-09-20

Amir's new book is out! ( Google preview )
2018-08-31
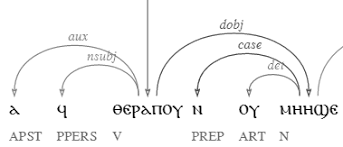
Amir and Mitchell published a paper on the Coptic Universal Dependency Treebank, which will be presented at the Universal Dependencies Workshop 2018
2018-08-21
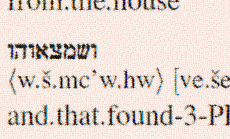
RFTokenizer achieves best accuracy on Hebrew morphological segmentation in a new paper at SIGMORPHON 2018
2018-08-08
The National Endowment for the Humanities just announced we won a big DHAG grant for research on Coptic !
2018-07-06

We're presenting a new paper about the Coptic Dictionary Online at COLING's LaTeCH-2018 workshop .
2018-06-27

Logan and Amir will present a paper on converting Stanford Dependencies to Universal Dependencies using multilayered corpus in LAW-MWE-CxG-2018 workshop at COLING2018
2018-06-06

Amir presented a paper about notional anaphora at CRAC2018
2018-05-10

Logan is presenting a paper about UD GUM at MASC SLL in UMBC
2018-05-02
The GUM corpus is now part of Universal Dependencies!
2018-05-01

V2.5.0 of Coptic Scriptorium corpora is released
2018-02-23

Amir gave a talk about discourse signals at JHU
Congratulations on Corpling lab's system DeDisCo winning the DISRPT 2025 Shared Task on Discourse Relation Classification!
Our paper presenting the UD Old English corpus of Cairo sentences , the first UD corpus of Old English, was accepted at SyntaxFest 2025 !
Our work on subjectivity in the anonotation of bridging anaphora will be presented during LAW XIX at ACL 2025!
Our work on the inter-genre variation of discourse relation signaling in RST was accepted to SCiL 2025 !
Our EMNLP 2024 paper presents a valuable genre-diverse PDTB-style dataset for English shallow discourse parsing across modalities, text types, and domains using a cascade of conversion modules leveraging enhanced RST annotations, thereby also enabling theoretical studies of discourse relation variation across frameworks
If you have any questions or feedback please let us know! If you'd like to join us: We accept new PhD and Masters students every year, please contact Amir Zeldes for more information.