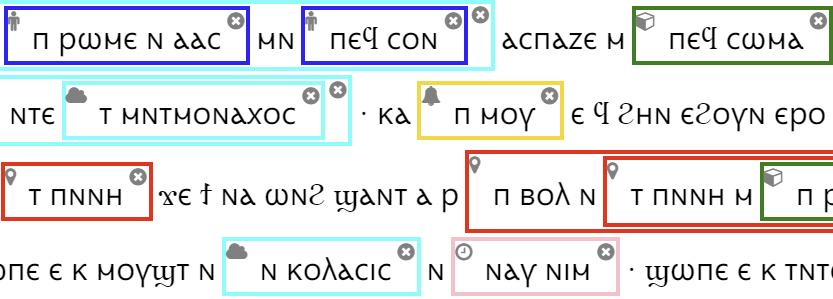
Search interfaces
The lab maintains two corpus search interfaces, which offer students and the general public access to language data and statistical analysis tools, as well as an online dictionary:
- The GU CQPWeb interface for large, flat annotated corpora
- ANNIS, search and visualization for richly annotated multilayer corpora
- Coptic Dictionary Online - a Coptic lexicon linked to corpora and frequency data
- Coptic Scriptorium Repository - browsable ancient Coptic texts with linguistic analyses