With the release of Version 2.6 of Universal Dependencies, our focus has shifted to handling Named and Non-Named Entity Recognition (NER/NNER) in Coptic data. As a result of intensive work by the Coptic Scriptorium team in the past few months, the development branch of the Treebank now contains complete entity spans and types for the entire data in the Treebank, which can be accessed here. Special thanks are due to Lance Martin, Liz Davidson and Mitchell Abrams for all their efforts!
What’s included?
- All data from the Coptic treebank (78 documents, approx. 46,000 words)
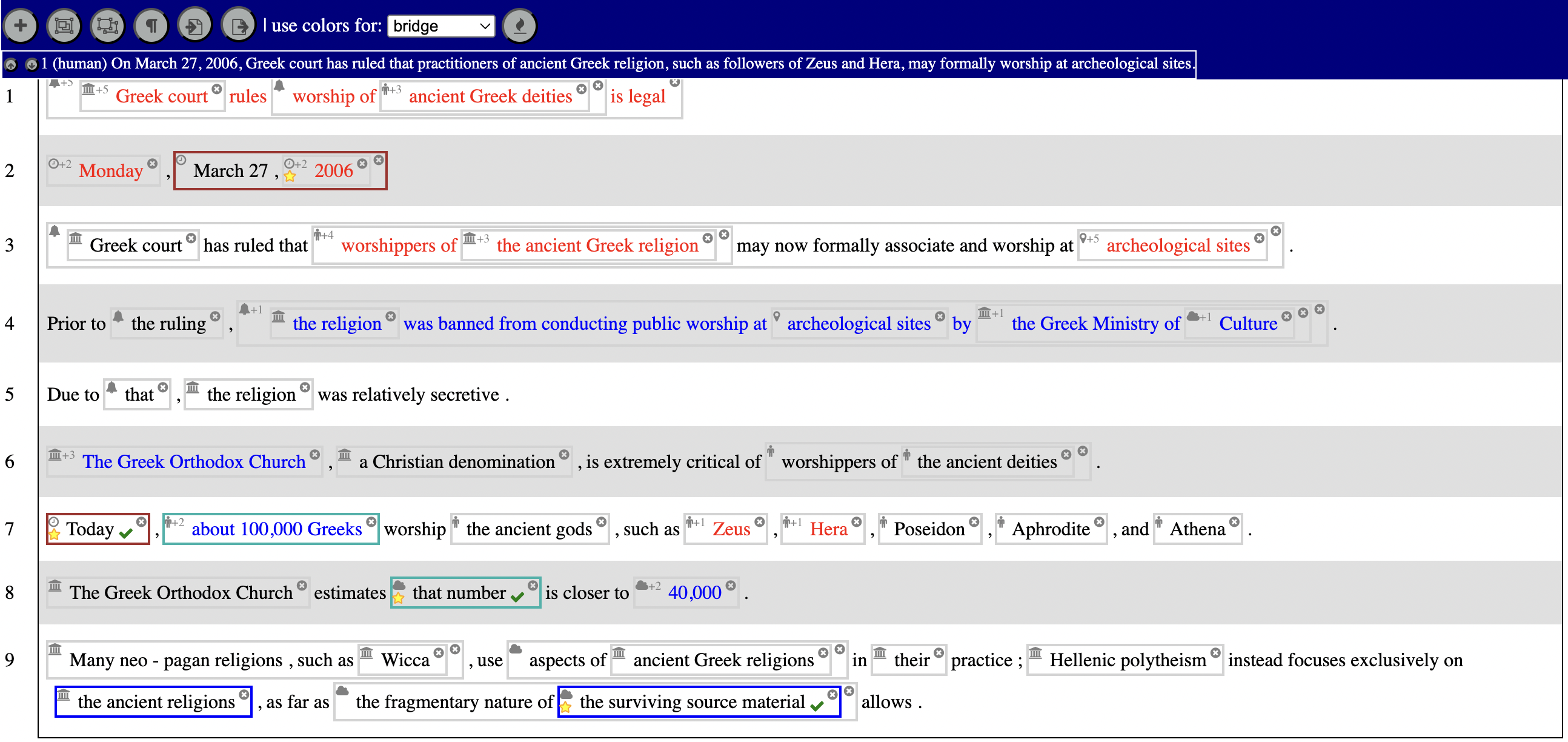
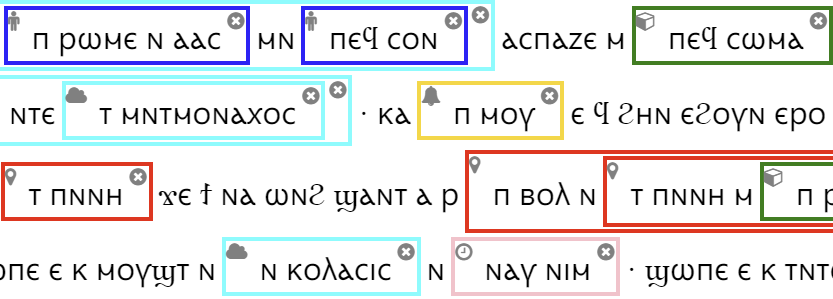
- All spans of text referring to a named or unnamed entity, such as “Emperor Diocletian”, “the old woman” or “his cell”.
- Nested entities contained in other entities, such a [the kingdom of [the Emperor Diocletian]]
- Entity types, divided into the following 10 classes: (English examples are provided in brackets)
What do we plan to do with this?
Entity annotations are a gateway to exposing and linking semantic content information from collections of documents. Having such annotations for all of our Coptic data will allow search by entity types (and ultimately names), enable analysis and comparison of texts based on the quantity, proportion and dispersion of entity types, facilitate identification of textual reuse disregarding either the entities involved or the ways in which they are phrased, and much more.
Over the course of the summer, our next goals fall into three packages:
- Natural Language Processing (NLP): Develop high-accuracy automatic entity recognition tools for Coptic based on this data, and make them freely available.
- Corpora: Enrich all of our available data with automatic entity annotations, which can be corrected and improved iteratively in the future.
- Entity linking: Leverage the inventory of named entities identified in the data to carry out named entity linking with resources such as Wikipedia and other DH project identifiers. This will allow users to find all mentions of a specific person or place, regardless of how they are referred to.
Since the tools and annotations are based only on Coptic textual input and subsequent automatic NLP, we envision including search and visualization of entity data for all of our corpora, including ones for which we do not have a translation. This means that data whose content could not be easily deciphered without extensive reading of the original Coptic text will become much more easily discoverable, by exploring entities in which researchers are interested.
Stay tuned for more updates on Coptic entities!