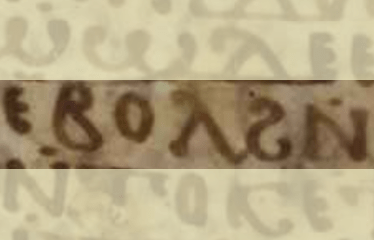
Coptic Scriptorium’s Natural Language Processing (NLP) tools now support two new features:
- Multiword expression recognition
- Detokenization (bound group re-merging)
Kicking off work on the new phase of our project, these new tools will improve inter-operability of Coptic data across corpora, lexical resources and projects:
Multiword expressions

The multiword expression ⲉⲃⲟⲗ ϩⲛ “out of” (from Apophthegmata Patrum 27, MOBG EG 67. Image: Österreichische Nationalbibliothek)
Although lemmatization and normalization already offer a good way of finding base forms of Coptic words, many complex expressions cross word borders in Coptic. For example, although it is possible to understand combinations such as ⲉⲃⲟⲗ ‘out’ + ϩⲛ ‘in’, or ⲥⲱⲧⲙ ‘hear’ + ⲛⲥⲁ ‘behind’ approximately from the meaning of each word, together they have special senses, such as ‘out of’ and ‘obey’ respectively. This and similar combinations are distinct enough from their constituents that they receive different lexicon entries in dictionaries, for example in the Coptic Dictionary Online (CDO), compare: ⲥⲱⲧⲙ, ⲛⲥⲁ and ⲥⲱⲧⲙ ⲛⲥⲁ.
Thanks to the availability of the CDO’s data, the NLP tools can now attempt to detect known multiword expressions, which can then be linked back to the dictionary and used to collect frequencies for complex items.
Many thanks to Maxim Kupreyev for his help in setting up multiword expressions in the dictionary, as well as to Frank Feder, So Miyagawa, Sebastian Richter and other KELLIA collaborators for making these lexical resources available!
Detokenization
Coptic bound groups have been written with intervening spaces according to a number of similar but subtly different traditions, such as Walter Till’s system and the system employed by Bentley Layton’s A Coptic Grammar, which Coptic Scriptorium employs. The differences between these and other segmentation traditions can create some problems:
- Users searching in multiple corpora may be surprised when queries behave differently due to segmentation differences.
- Machine learning tools trained on one standard degrade in performance when the data they analyze uses a different standard.
In order to address these issues and have more consistent and more accurately analyzed data, we have added a component to our tools which can attempt to merge bound groups into ‘Laytonian’ bound groups. In Computational Linguistics, re-segmenting a segmented text is referred to as ‘detokenization’, but for our tools this has also been affectionately termed ‘Laytonization’. The new detokenizer has several options to choose from:
- No merging – this is the behavior of our tools to date, no modifications are undertaken.
- Conservative merging mode – in conservative merging, only items known to be spelled apart in different segmentations are merged. For example, in the sequence ϩⲙ ⲡⲏⲓ “in the-house”, the word ϩⲙ “in” is typically spelled apart in Till’s system, but together in Layton’s. This type of sequence would be merged in conservative mode.
- Aggressive merging mode – in this mode, anything that is most often spelled bound in our training data is merged. This is done even if the segment being bound by the system is not not one that would normally be spelled apart in some other conventional system. For example, the sequence ⲁ ϥⲥⲱⲧⲙ “(PAST) he heard”, the past tense marker ⲁ is a unit that no Coptic orthographic convention spells apart. It is relatively unlikely that it should stand apart in normal Coptic text in any convention, so in aggressive mode it would be merged as well.
- Segment at merge point – regardless of the merging mode chosen, if any merging occurs, this option enforces the presence of a morphological boundary at any merge point. This ensures that merged items are always assigned to separate underlying words, and receive part of speech annotations accordingly, even if our machine learning segmenter does not predict that the merged bound group should be segmented in this way.
The use of these options is expected to correspond more or less to the type of input text: for carefully edited text from a different convention (e.g. Till), conservative merging is with segmentation at merge points is recommended. For ‘messier’ text (e.g. older digitized editions with varying conventions, such as editions by Wallis Bugde, or material from automatic Optical Character Recognition), aggressive merging is advised, and we may not necessarily want to assume that segments should be introduced at merge points.
We hope these tools will be useful and expect to see them create more consistency, higher accuracy and inter-operability between resources in the near future!