Visualization of RNN output highlighting words most likely to signal a discourse relation
... in search of discourse signals! We now know a lot about what cues people use to identify discourse relations, but can we teach computers to notice the same signals?
Working with Rhetorical Structure Theory (RST, Mann & Thompson 1988), researchers at SFU (Taboada & Das 2013) studied how people recognize discourse relations in text, such as cause (readers should understand what happened in sentence A is the cause of what happened in sentence B), evidence (e.g. clause B is given to make us believe A), or contrast (A and B differ in some relevant respect). They took the RST Discourse Treebank (Carlson et al. 2003), which gives RST analyses for 180,000 tokens of Wall Street Journal data, and annotated them again for signals - words, constructions, and other cues that tell readers which relation is present. They found that simple discourse markers, such as 'because' (signalling cause) or 'but' (signalling contrast), signal only around 22% of relations, while almost 78% of signals were more complex. In total, over 86% of relations were signaled in some way, including by repeating salient words (mentioning the same person), using genre conventions, or item of graphical layout. You can read more about their work here.
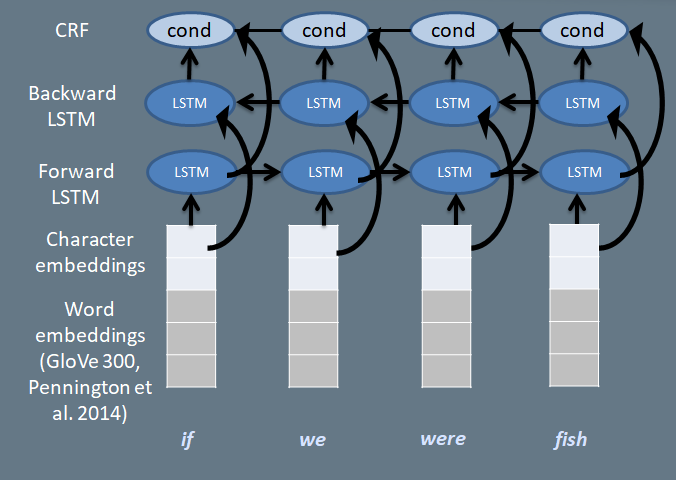
Recent advances in Computational Linguistics have made it increasingly possible for computers to recognize the presence of the same discourse relations automatically using Recurrent Neural Networks (e.g. Braud et al. 2017, see Morey et al. 2017 for an overview). However, RNNs can be
good at classifying language, while giving us little insight into how or why certain utternaces are classified. In this experiment, we decided to train an RNN (specifically a biLSTM-CRF) to recognize relations from the RST Discourse Treebank, but instead of outputting the correct relation, we designed it to output a probability distribution over all relations at each word, while reading the text backwards and forwards. This means that every word is evaluated in context, based on adjacent words: a word like 'but' can be important in one case, or not important in another. The basic architecture is sketched out below (for more details see Zeldes 2018, Chapter 6).
biLSTM-CRF with word and character embeddings classifying discourse relations
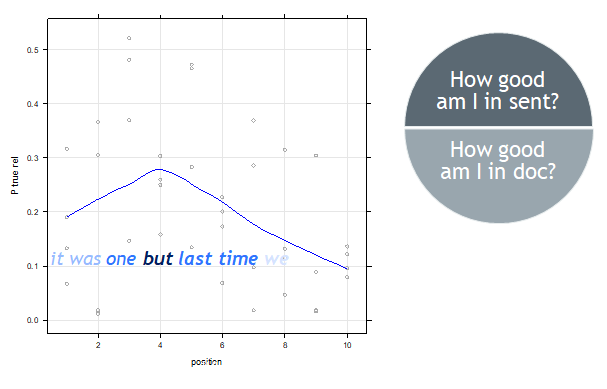
To visualize the signals the network notices, we shade each word in each sentence based on the softmax probability the network assigns to the correct relation at that point. 50% of
each word's darkness comes from 'how good it is in this sentence' and 50% come from 'how good it is in this text'.
For example, if the network is reading a contrast statement, and sees the word 'but', it might give 60% probability that this is a contrast, but also 30% that it's concesssion and 10% divided among other relations. If this is the highest probability word for the correct relation (contrast) in this sentence, the word receives the maximum of 50% darkness for 'how good it is in the sentence'. Suppose that in the entire text, no other word scored more than 60% for its correct relation. In this case, the word 'but' will receive another
50% darkness and be visualized as completely black. This is illustrated below.
Shading words by proportion of maximum softmax for the correct relation in the sentence and in the text
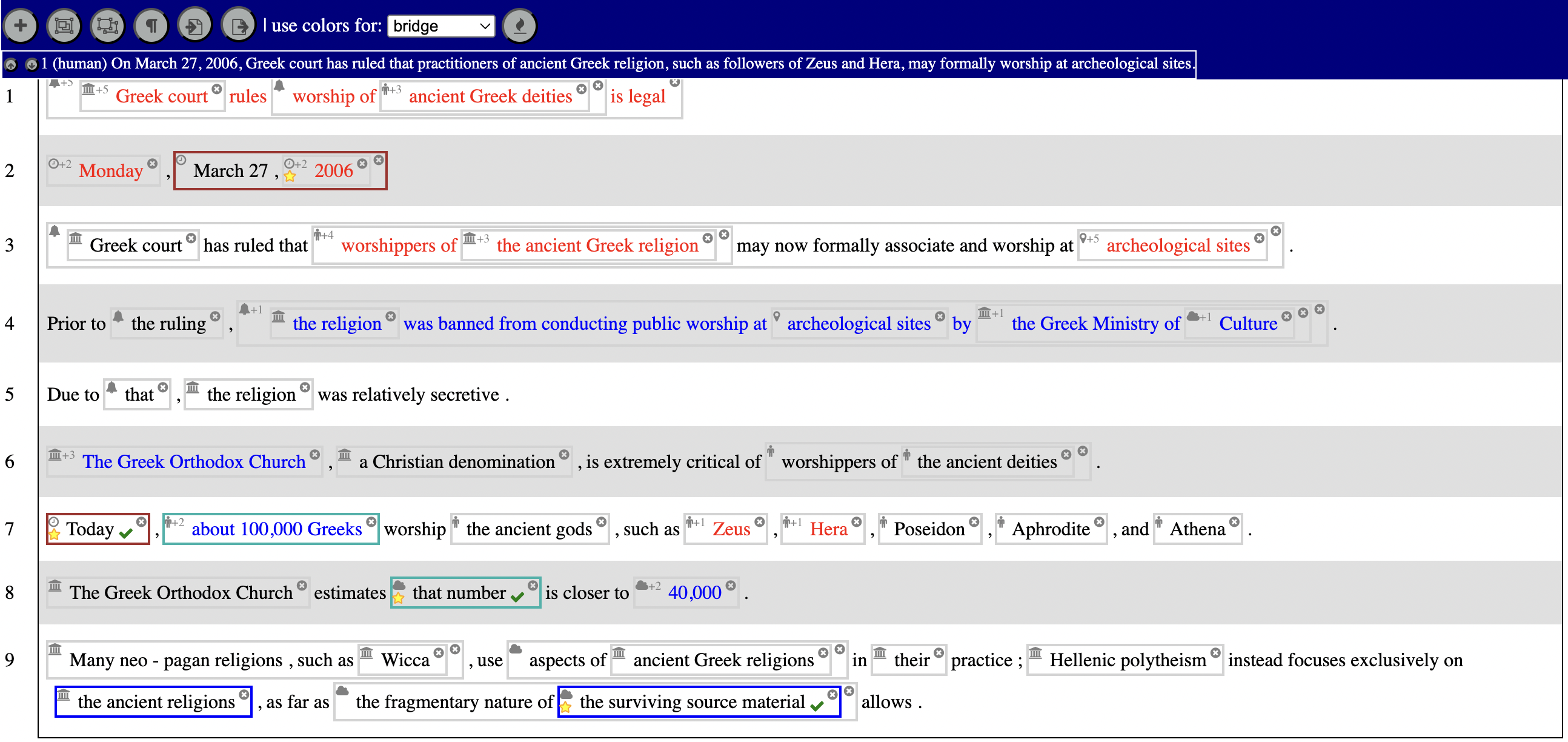
So how does the network compare to humans? It notices some of the same things, but also some different ones. Below Janet Liu from our lab identified words corresponding to human
signaling annotation, where words are flagged categorically as signals (bold) or not signals based on the annotations of the RST Discourse Treebank. Next to these you can see the network output, with gradual shading. Note that we are not learning to detect signals by training on signaling annotation: the network is really learning how to recognize relations, and outputting signals as a by-product. It's relatively easy to catch discourse markers, such as 'then', or a relative pronoun 'which' signaling an elaboration. The challenge we are working on is figuring out what features the network needs to know about beyond just word forms in order to notice discourse relations reliably, for example engineering features to catch meaningful repetitions ('Senator Byrd' below).
Discourse relation signals annotated by a human (top) and an RNN (bottom)
To learn more about this work, check out this talk:
If you have any questions or feedback please let us know! If you'd like to join us: We accept new PhD and Masters students every year, please contact Amir Zeldes for more information.