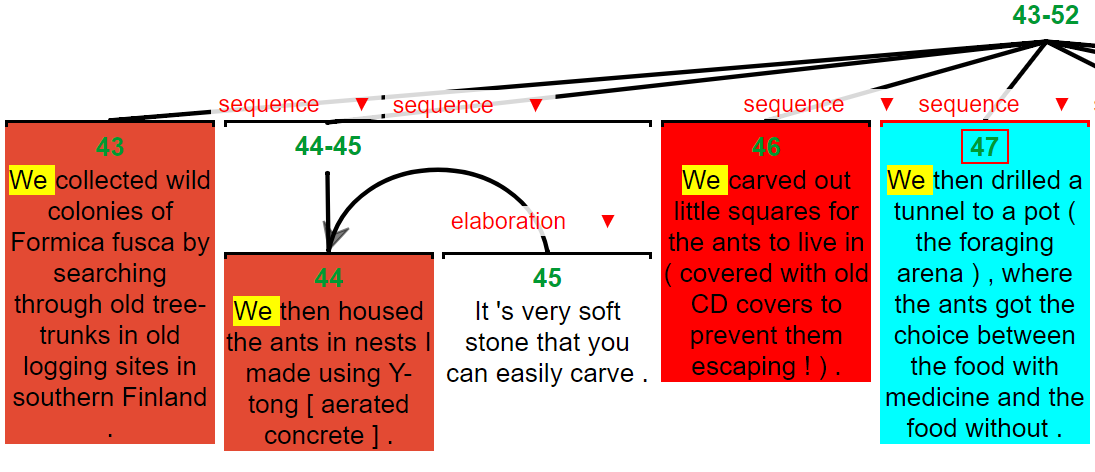
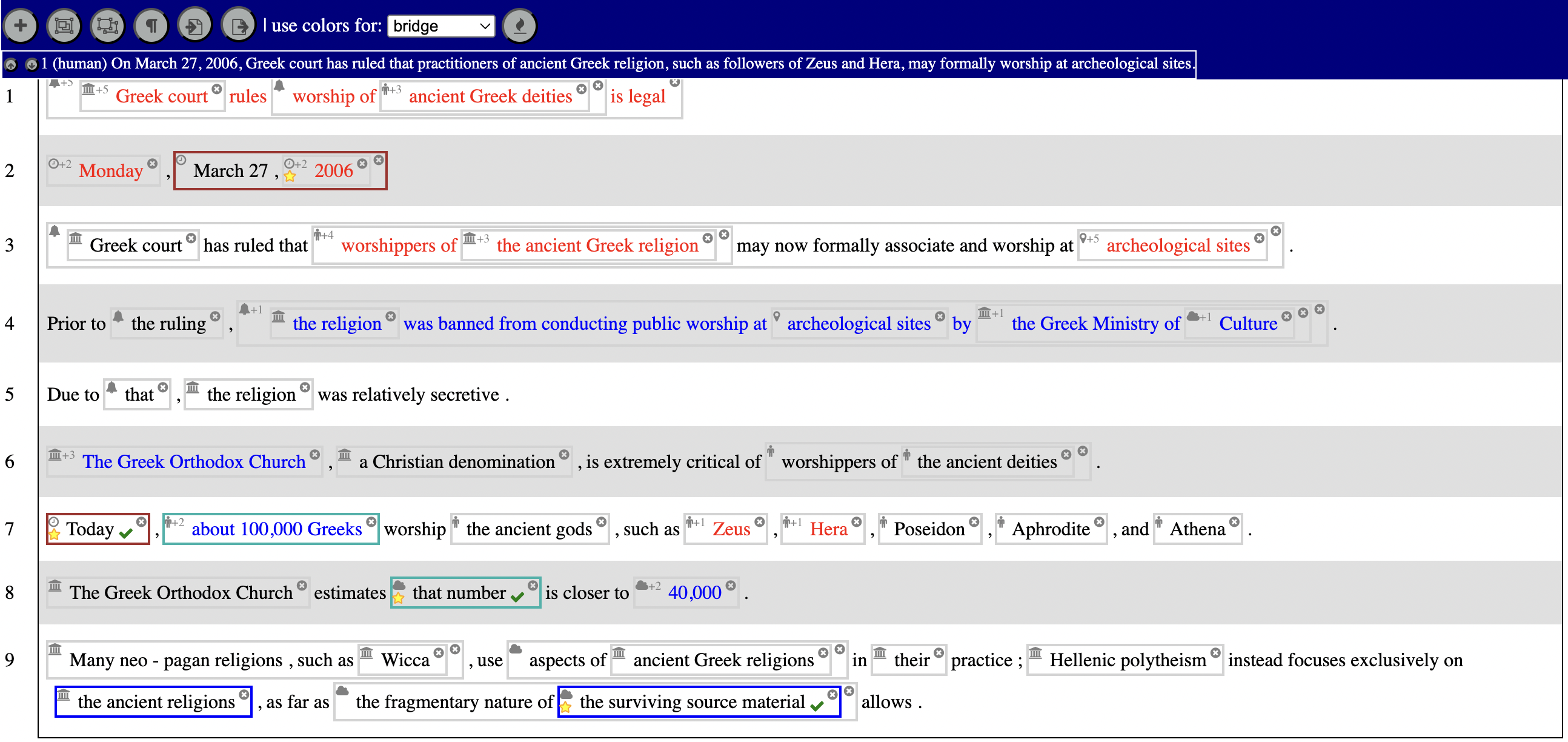
A heatmap of back reference likelihood for a pronoun in the blue unit
Does discourse structure constrain where we talk about what? Research on recurring mentions within discourse graphs shows
back-reference is sensitive to the reasons why sentences and groups of sentences are uttered. In the image above, we fixate on a target
sentence in blue, and predict how likely it is that a pronoun inside it will have an antecedent in some other unit (without peeking at the words!).
Redder units are more likely to contain an antecedent.
There are several frameworks for describing discourse graphs - we use Rhetorical Structure Theory (Mann & Thompson 1988), which posits that text are "trees of clauses".
Much like sentences form trees of words, discourse trees can lump together multiple clauses into complex discourse units, which often correspond to coherent sections or paragraphs in writing, and different
discourse units have different functions. Instead of function like 'subject' and 'object', discourse units have fiunctions such as expressing 'background information', 'evidence' or 'cause'. The example below
shows how these relations coalesce to form a coherent discourse.
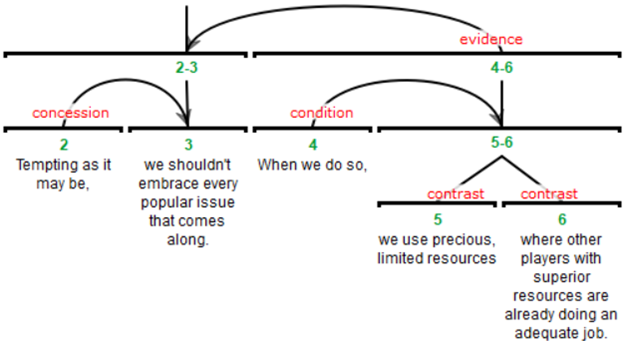
Example analysis of a discourse fragment in RST (source: RST website)
The idea that discourse trees constrain what can be referred to where goes back at least to Polanyi's (1988) 'stack of discourse units', determining entities available for pronominalization at each point (e.g. pronouns should)
refer back to words inside some maximal complex unit. This was formalized in RST by Veins Theory (Cristea et al. 1998) usings Domain of Referential Accessibility (DRA): sub-parts of a discourse graph commanding
a unit with a pronoun are legitimate regions for back reference.
Although subsequent work (Tetreault & Allen 2003) has shown that a categorical constraint forbidding pronouns from referring back to words outside their DRA is wrong, our recent work has shown that, when used
quantitatively alongside other predictors, we can build predictive heatmaps like the one above. For more information see the paper linked below!
If you have any questions or feedback please let us know! If you'd like to join us: We accept new PhD and Masters students every year, please contact Amir Zeldes for more information.